こんにちは。UpGear運営者のKです。
話題のNotebookLMを使ってみて、せっかく読み込ませた資料が「謎の記号だらけ」になってしまい、頭を抱えちゃっていませんか…!!
いざ業務で使おうとした矢先にエラーが出ると、本当に焦りますよね。
実はこれ、一時的なバグではありません。
日本語環境特有のファイル仕様や、文字コードの不一致が原因で起こる「AIの読み取りエラー」なんです。
この記事では、NotebookLMの文字化けについて、なぜ起きるのかという根本的な理由から、誰でもすぐできる具体的な解決ステップまでを分かりやすく解説します!
結論を先にお伝えすると、最速の解決策は「テキストの直接貼り付け」、そして恒久的な対策は「Googleドキュメントを経由したPDFの再生成」になります。
これさえ知っておけば、AIのリサーチで立ち止まることはもうありませんよ!
- AIの回答が意味不明になってしまう根本的な理由
- PDF読み込み時に発生するエラーの正体
- 文字コードやフォント埋め込みの仕組み(専門用語なしで解説!)
- トラブルをサクッと回避する具体的な解決手順
\文字化けしない完璧なPDFをサクッと作成!/

NotebookLM文字化けを直す方法と対策は?

NotebookLMを使いこなす上で、避けて通れないのが「日本語特有のトラブル」です。
まずは、具体的にどんな現象が起きて、何が悪さをしているのかをサクッと紐解いていきましょう!
AIが「意味不明な回答」をしてしまうリスク
せっかく読み込ませた資料なのに、AIが全く意味をなさない回答をしてしまうのが一番の恐怖ですよね。
これは、AIの頭の中でテキストが「別の文字」として勘違いされ、本来の文脈とは無関係な言葉と勝手に結びついてしまうからです。
たとえば、管理画面では「正常にアップロード完了」と見えていても、いざAIに質問するとこんなことが起きます。
- 資料には一切書かれていない謎の情報を語り出す
- 意味不明な記号の羅列だけが返ってくる
これ、本当にギョッとしますよね…!!
もしビジネスの場でこの誤情報を鵜呑みにして企画書を作ってしまったら、取り返しのつかないミスに繋がりかねません。
AIの出力をそのまま使う前に、まずは「AIが資料の文字を正しく読めているか」を最初の段階でしっかりチェックするクセをつけましょう!
【注意点】
文字化けしたまま利用を続けると、AIがもっともらしいウソをつく「ハルシネーション」の直接的な原因になります!「なんだか回答がおかしいな?」と感じたら、すぐにソース(元の資料)が文字化けしていないか疑ってください。
PDF読み込みエラーと無限ループ
ファイルを追加しようとしたら、読み込みバーが途中でストップして一生終わらない…というエラーもよくあります。
これは、PDF内部のデータ破損や、見えない「パスワード保護」がAIのクローラー(情報を読み取るシステム)を弾き返している状態です。
ファイルの容量はオーバーしていないのに、なぜか数時間も「読み込み中」のままだったり、ファイル名が赤文字でエラー表示されたりすると、本当にイライラしちゃいますよね(笑)
この無限ループに陥ったら、ファイルにかけられている制限を解除するか、別のファイル形式でアップロードし直すのが正解です。
複雑なレイアウトにおける視覚的崩壊
インフォグラフィックやスライド作成などの視覚的な生成機能で、日本語が四角い「豆腐(□)」の記号に置き換わってしまう現象です。
AI自身はテキストの内容を理解していても、最終的に画面へ出力(レンダリング)する際、システム側で日本語フォントの準備が追いついていないために起こります。また、音声概要(Audio Overview)においても、元の資料が文字化けしていると、AIホストが意味不明な内容を話し出したり、読み上げが支離滅裂になったりするトラブルに直結しちゃうんです。
2026年の最新モデル(Nano Banana Pro等)へのアップデートにより、UTF-8準拠の資料であれば「豆腐」現象はほぼ解消されました。
しかし、古い規格のPDFやShift_JISベースの資料を読み込ませた場合、画像内の文字が消えたり、音声の台本そのものが崩壊したりするリスクは依然として残っています。せっかくの図解入りプレゼン資料が、注釈の見えない「豆腐だらけ」の画像になってしまうのは、視覚的な資料としてかなり致命的ですよね…!!
視覚的な要約機能をフル活用したいなら、デザインや装飾を極力省いた「シンプルなテキストベースの資料」をソースとして用意するのが、現時点での一番の予防策になります。
【ポイント】
「豆腐(□)」が出るのは図解やスライド生成時、音声の崩壊は「読み込み段階の文字化け」が原因。まずはソースが正しく読めているか確認しましょう!
UTF8とShiftJISの非互換性
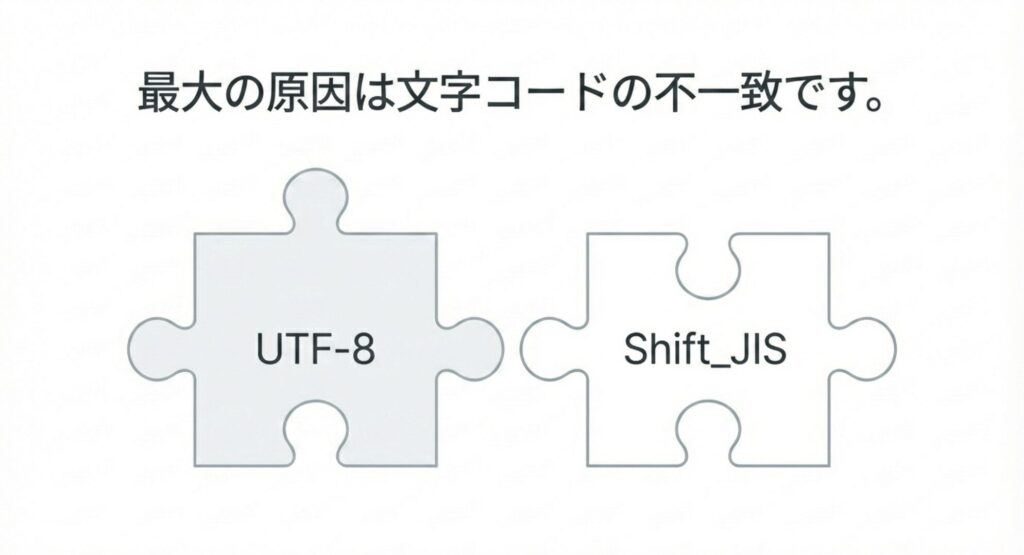
文字化けを引き起こす最大の戦犯は、AIが基準とする「UTF-8」と、日本の古いサイトで使われる「Shift_JIS」という文字コードの不一致です。
Googleのシステムは国際標準である「UTF-8」で動いていますが、日本の公的機関などの古いシステム(例:衆議院の公式サイト等)では未だに「Shift_JIS」が多用されています。ルールが違う「背番号」をAIが無理やり世界基準で読もうとするから、文字が盛大にズレて、全く別の意味に変わってしまうんです。
実際、古い規格のウェブページをURLで直接読み込ませた結果、本来の内容とは無関係な「専門用語」としてAIが誤認してしまった事故も報告されています。これは単なる表示の崩れではなく、AIの推論回路に「間違った燃料」を供給しているようなもの。これでは、どんなに高性能なAIでも正しい回答は出せません。
ウェブサイトの情報をソースにする場合は、直接URLを貼るのではなく、一度ブラウザでPDFとして保存し直すなどの「翻訳ミス(文字コードの不一致)」を防ぐ対策が絶対に欠かせません。
フォント埋め込み不足とCMap欠陥
PDF内部で日本語フォントが正しく「埋め込み」されていなかったり、文字情報のマッピングに欠陥があることも文字化けの原因になります。
PDFには文字の形とコードを結びつける「CMap」という設計図がありますが、PDF作成時の設定が甘いと、AI側で「どの文字を当てはめればいいか」が迷子になってしまうんです。
海外製の安いPDF作成ソフトで作ったものや、複合機でただスキャンしただけの「画像としてのPDF」は要注意。人間の目には普通に見えても、AIにとっては「文字情報がスッポリ抜けた単なる画像」になっちゃいます。
PDF化する際は必ず「全フォントを埋め込む」設定にするか、確実にテキストデータが保持される方法を選びましょう!
NotebookLM文字化けを直す方法と対策の手順は?

原因がわかったところで、いよいよ実践編です。
ファイルのアップロード方法を変えるか、資料の文字コードを整えることでスパッと解決できます。
今すぐ試せる裏技から、プロ向けの根本対策まで順番に解説していきますね!
テキスト直接入力による最速の回避策
最も早くて確実な解決策は、PDFなどのファイルをアップロードせず、文章をコピーして「テキストを直接貼り付ける」ことです。
ファイルごと読み込ませるから、文字コードの違いや見えない制限に引っかかってしまうわけです。テキストデータだけを抜き出して直接入力してしまえば、こうしたシステム側の誤認識を完全にスルーできちゃいます!
やり方は驚くほどシンプルです。
- 元の資料(PDFやウェブサイト)を開き、必要な範囲を全選択してコピー。
- NotebookLMの「ソースを追加」画面で、「テキストをコピーして貼り付ける」を選択。
- 余計な改行や変な記号が入っていたら、ササッと消して整理してから登録。
私自身、急いでいる時に限ってPDFがエラーになって「もう…!!(笑)」って発狂しそうになったんですが、この方法を知ってからは一瞬で解決するようになりました。
とにかく今すぐAIに答えてほしい時は、ファイル形式にこだわらず「直接コピペ」を試してみてくださいね!
GoogleドキュメントでのPDF再生成

資料をきちんとファイルとして管理したい場合の最適解は、文字化けするPDFの内容を一度Googleドキュメントに貼り付け、そこからPDFとして再保存することです。
NotebookLMはGoogleのサービスなので、同じGoogleのシステム(ドキュメント)から出力されたファイルなら、AIのクローラーが圧倒的に読みやすい「完璧な構造(UTF-8準拠など)」に自動変換されるからです。
- 文字化けするPDFのテキストをコピーし、Googleドキュメントに貼り付け。
- メニューの「ファイル」>「ダウンロード」>「PDFドキュメント(.pdf)」を選んで保存。
- Wordを使う場合は「名前を付けて保存」からPDF形式を選び、オプションの「フォントを埋め込む」に必ずチェックを入れる。
これだけで、読み込みエラーの発生率は劇的に下がります。
ただ…ぶっちゃけ、「毎回この変換作業をやるのは面倒くさい!」と思う方も多いのではないでしょうか?
大量の資料を扱うビジネスパーソンにとって、ちまちまドキュメントにコピペする時間は明白なタイムロスです。
「時間を無駄にしたくない」「最初からAIが完璧に読めるPDFを一発で作りたい」という方は、専用のPDFソフトを導入して根本的に解決するのが一番賢い投資かなと思います。
\面倒な変換作業をスキップ!AIが100%読めるPDFに/
キャッシュ削除とシークレットモード
パソコン環境が原因で文字化けが起きている場合は、ブラウザのキャッシュを削除するか、シークレットモードで開き直すのが有効です。
ブラウザに古いデータ(キャッシュやCookie)が溜まりすぎていると、NotebookLMのシステムと喧嘩してしまい、正常にテキストを読み取れなくなるケースがあるからです。また、裏で動いている拡張機能(アドオン)が悪さをしていることも少なくありません。
「なんか動きが重いな」「いつもは読めるファイルなのに!」という時は、サクッとお掃除してみましょう。
【ブラウザのメンテナンス手順】
- ブラウザの設定から「閲覧履歴データの削除」を選び、キャッシュとCookieをクリア。
- Windowsなら「Ctrl+Shift+N」、Macなら「Cmd+Shift+N」を押してシークレットウィンドウを開き、NotebookLMに再アクセス。
私も何をやってもエラーになる日があって絶望したんですが、シークレットモードで開いたらあっさり直っちゃった経験があります(笑)
ただ、こういったブラウザのキャッシュ削除やシークレットモードって、「どこをイジればいいか不安」「間違えてパスワードとか全部消えちゃったらどうしよう…」と、パソコンの奥深くを触るのが怖いと感じる方もいますよね。
もし、自分であれこれ設定して余計にPCの調子が悪くなるのが不安なら、無理せずプロに丸投げしてしまうのが一番安心で確実な方法です。
\PCの不具合や設定エラーをプロに丸投げ!/

代替AIによる画像OCRとYAML化
図解や表など、テキスト化が難しい複雑な資料の場合は、Geminiなど他のAIに画像を読み込ませて「構造化データ(YAML)」に変換してもらうのが最強の裏技です。
複雑なレイアウトのPDFはNotebookLM単体だと文字の配置を勘違いしやすいですが、画像解析に特化したAIを間に挟めば、視覚的な構造を保ったまま正確にテキストを抜き出せるからです。
以下の表は、難しい資料を読み込ませる際に役立つ代替AIの比較です。
(※料金は一般的な目安です。最新情報は各公式サイトをご確認ください)
| ツール名 | 日本語PDF解析精度 | 主な特徴 |
|---|---|---|
| Gemini 1.5 Pro | 非常に高い | NotebookLMの基盤。長文解析に強い |
| Claude 3.5 Sonnet | 最高評価 | 画像内の文字配置の理解が極めて正確 |
| ChatGPT Plus | 非常に高い | 多角的な要約が可能 |
やり方は、文字化けする箇所のスクショを撮り、Geminiなどに「この画像内の日本語を読み取って、YAML形式にして」とお願いするだけ!出てきたテキストをNotebookLMに貼り付ければ完璧です。
グラフィック中心の資料でどうしてもうまくいかない時は、無理せず他の最新AIに頼るのが結果的に一番の近道ですね。
組織的な文字コードとフォント標準化
会社やチームで根本的な対策を行うなら、資料作成時の「使用フォントの限定」と「UTF-8の標準化」をルール化することが最も確実です。
個人のパソコン環境に依存せず、最初からAIが読みやすい規格で作っておけば、文字化けや解析不能のエラーを100%未然に防げるからです。
NotebookLMのソース制限は1ファイル200MB、最大50万語ですが、巨大なファイルほどエラーが起きやすいので、キレイなデータ作りが欠かせません(出典:Google 検索 ヘルプ『NotebookLM について』)。
【推奨されるドキュメント作成ルール】
- フォントの統一:MSゴシックや游明朝など、OS標準の日本語フォントのみを使用する。
- PDFの保存設定:サブセット化ではなく「全フォント埋め込み」を徹底する。
- 過度な装飾の禁止:AIが誤認しやすい過度な網掛けや、特殊な絵文字を使わない。
- Webページの保存:古いサイトは直接URLを貼らず、ブラウザの印刷機能から「PDFとして保存」して文字コードを変換する。
これを徹底するだけで、「誰がアップロードしてもエラーにならない」快適なチーム環境が作れちゃいます!
これからのAI時代、ただ人間が読みやすいだけでなく「AIが解釈しやすいデータ作り」を意識することが、知的生産性をグッと高めるカギになりますね。
そして、AIツールをストレスなく使いこなし、何時間もリサーチに没頭するなら、あなた自身の「作業環境」もアップデートすることを強くおすすめします。
いくらソフトの設定を完璧にしても、座りっぱなしで首や腰が痛くなっては元も子もありませんよね。
\長時間のAIリサーチでも疲れ知らずの集中力を!/

総括:NotebookLM文字化けを直す方法と対策

NotebookLMの文字化けを直す方法と対策の最適解は、エラーが起きたら「テキストの直接貼り付け」で素早く回避し、日頃から「Googleドキュメント経由のPDF作成」でデータを整えることです。
日本語特有の文字コード(Shift_JISなど)や、フォント埋め込みの欠陥というシステム上の壁はあります。ですが、私たちがデータを渡す際のちょっとした工夫で、NotebookLMの潜在能力を100%引き出すことは十分に可能なんです!
【文字化け対策のおさらい】
- 【最速】テキストをコピーして直接貼り付ける
- 【確実】Googleドキュメントに貼ってPDF化する
- 【環境】ブラウザのキャッシュ削除やシークレットモードを試す
- 【高度】ClaudeやGeminiの画像読み取りでテキスト化する
文字化けという小さなハードルで、NotebookLMの素晴らしい分析力を諦めてしまうのは本当にもったいないです!
ぜひこの記事の対策を試して、快適なAIリサーチ環境を手に入れてくださいね。
もし「どうしても自力でPCのトラブルを解決できない…」と行き詰まってしまったら、一人で悩み続けずにプロのサポートを頼るのも立派な解決策です。
\AIツールのエラーやPCトラブルをいますぐ解決/